# 梯度下降算法实现 defgradient_descent(X, y, lr=0.1, n_iterations=1000): m = len(y) # 初始化参数 w = np.random.randn(1) b = 0
loss_history = []
for iteration inrange(n_iterations): # 计算模型预测 y_pred = w * X + b # 计算损失 loss = (1 / (2 * m)) * np.sum((y_pred - y) ** 2) loss_history.append(loss) # 计算梯度 dw = (1 / m) * np.sum((y_pred - y) * X) db = (1 / m) * np.sum(y_pred - y) # 更新参数 w = w - lr * dw b = b - lr * db
if iteration % 100 == 0: print(f"Iteration {iteration}: Loss = {loss}, w = {w[0]}, b = {b}")
return w, b, loss_history
# 设置超参数 learning_rate = 0.1 n_iters = 1000
# 运行梯度下降 w_opt, b_opt, loss_hist = gradient_descent(X, y, lr=learning_rate, n_iterations=n_iters)
print(f"Optimized parameters: w = {w_opt[0]}, b = {b_opt}")
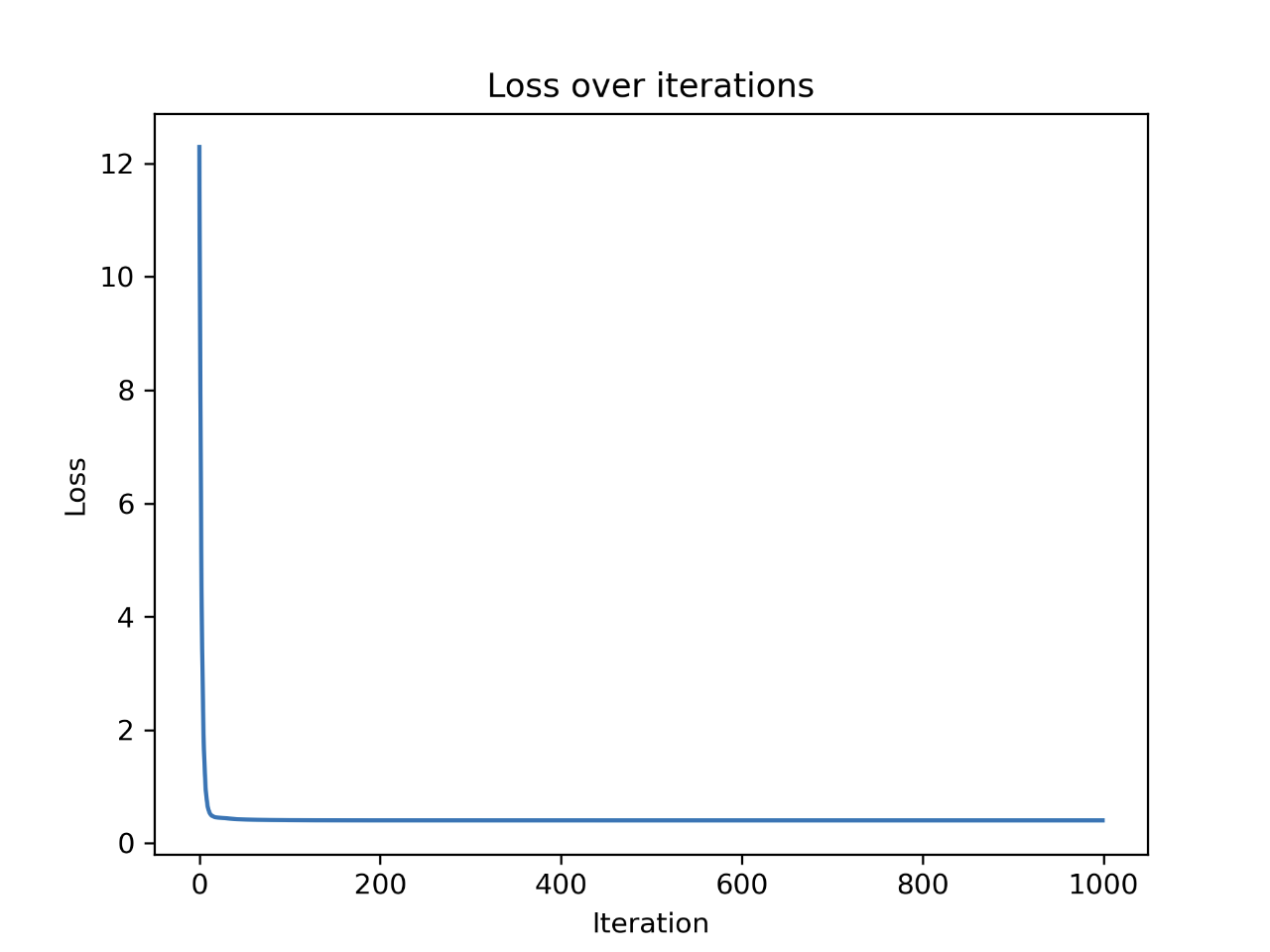
# 绘制损失函数变化 plt.plot(loss_hist) plt.xlabel('Iteration') plt.ylabel('Loss') plt.title('Loss over iterations') plt.show()
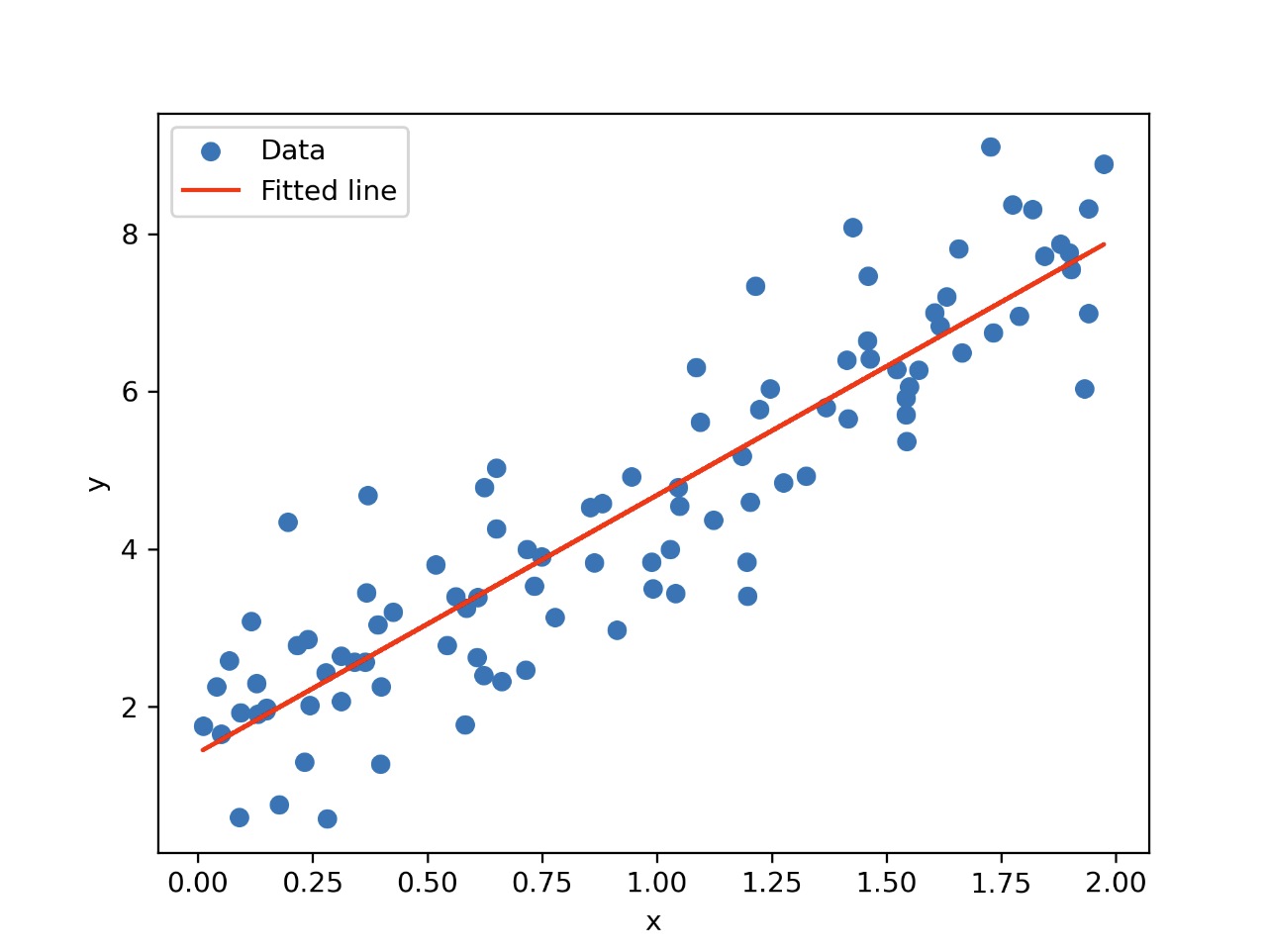
# 绘制拟合结果 plt.scatter(X, y, label='Data') plt.plot(X, w_opt * X + b_opt, color='red', label='Fitted line') plt.xlabel('x') plt.ylabel('y') plt.legend() plt.show()
代码解释
输出:
1 2 3 4 5 6 7 8 9 10 11
Iteration 0: Loss = 12.288322478218705, w = 0.5482405149791566, b = 0.4477958365103154 Iteration 100: Loss = 0.406609440292755, w = 3.141471680138024, b = 1.560792222398323 Iteration 200: Loss = 0.40340042917083907, w = 3.246885681182567, b = 1.4414032188965682 Iteration 300: Loss = 0.4032958078369932, w = 3.265919363304535, b = 1.419846193018257 Iteration 400: Loss = 0.40329239693466856, w = 3.2693561084441964, b = 1.4159538298150631 Iteration 500: Loss = 0.4032922857312052, w = 3.2699766513890296, b = 1.4152510199102504 Iteration 600: Loss = 0.40329228210570994, w = 3.2700886973891645, b = 1.4151241196862692 Iteration 700: Loss = 0.4032922819875102, w = 3.2701089285532627, b = 1.4151012064251764 Iteration 800: Loss = 0.4032922819836566, w = 3.270112581517226, b = 1.4150970691784694 Iteration 900: Loss = 0.40329228198353106, w = 3.2701132411009084, b = 1.415096322152097 Optimized parameters: w = 3.270113359743099, b = 1.4150961877812085